
软件分析-指针分析
指针分析
Foundations
rules
指针分析需要关注的域

- 变量 V
- 属性 F
- 对象 O
- 对象的成员属性
- 指针 包括变量+对象的field
处理规则
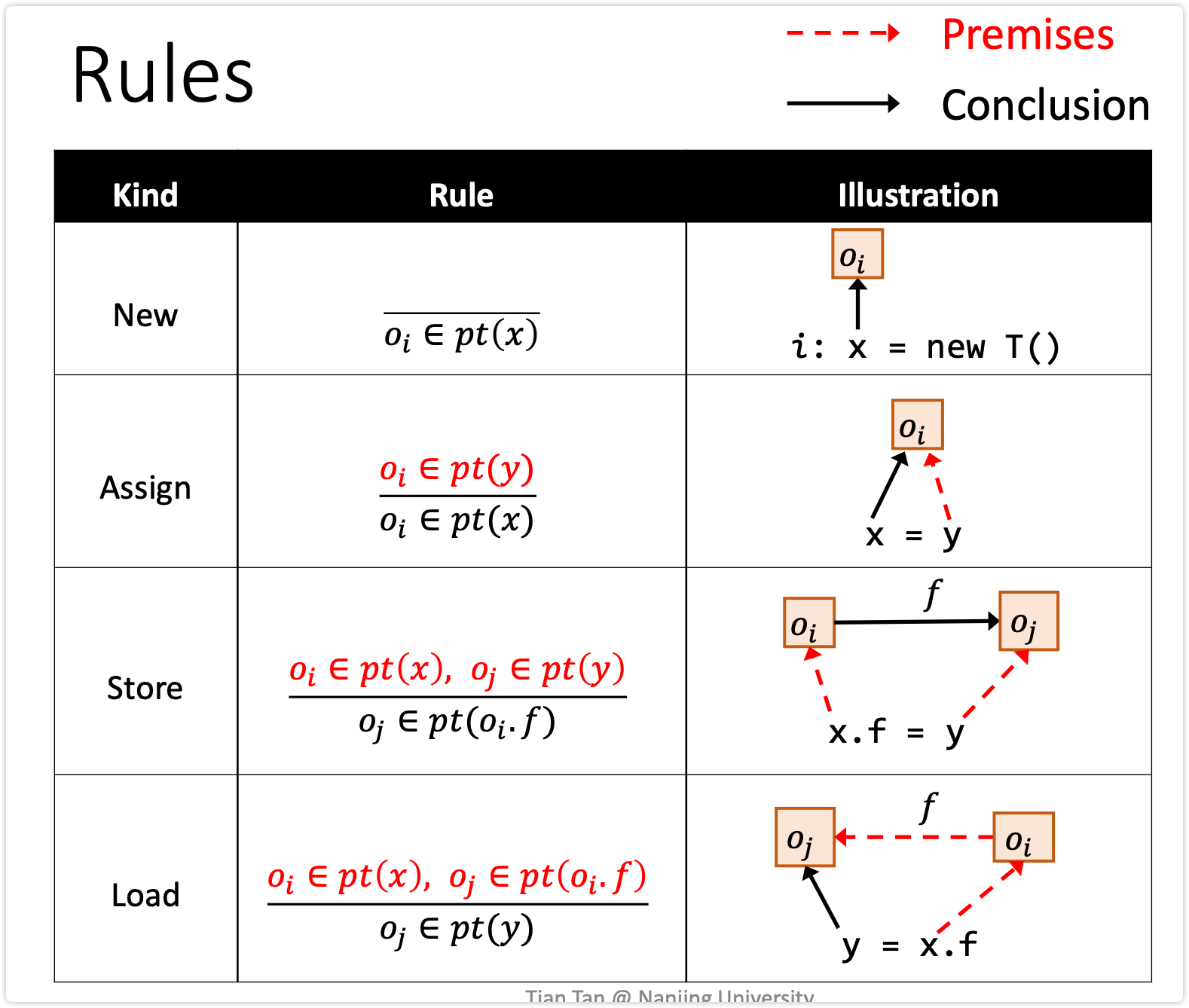
横线上是前提条件,下面是推到出的
- New 直接把x指向oi
- Assign y指向的加入x的集合
- Store x指向oi,y指向oj,同时把y存到x.f里,就把oj指到oi.f
- Load x指向oi,把x.f赋值给y,且oi.f指向oj,就把y指到oj
implement
主要部分:在指针之间互相传播
关键:当一个指针集合变化、更新时,要把变化的部分传播给与它相关的其他指针
PFG 指针流图
有向图
节点:程序中的指针
边:指针指向的对象在指针间的流动
PFG建边
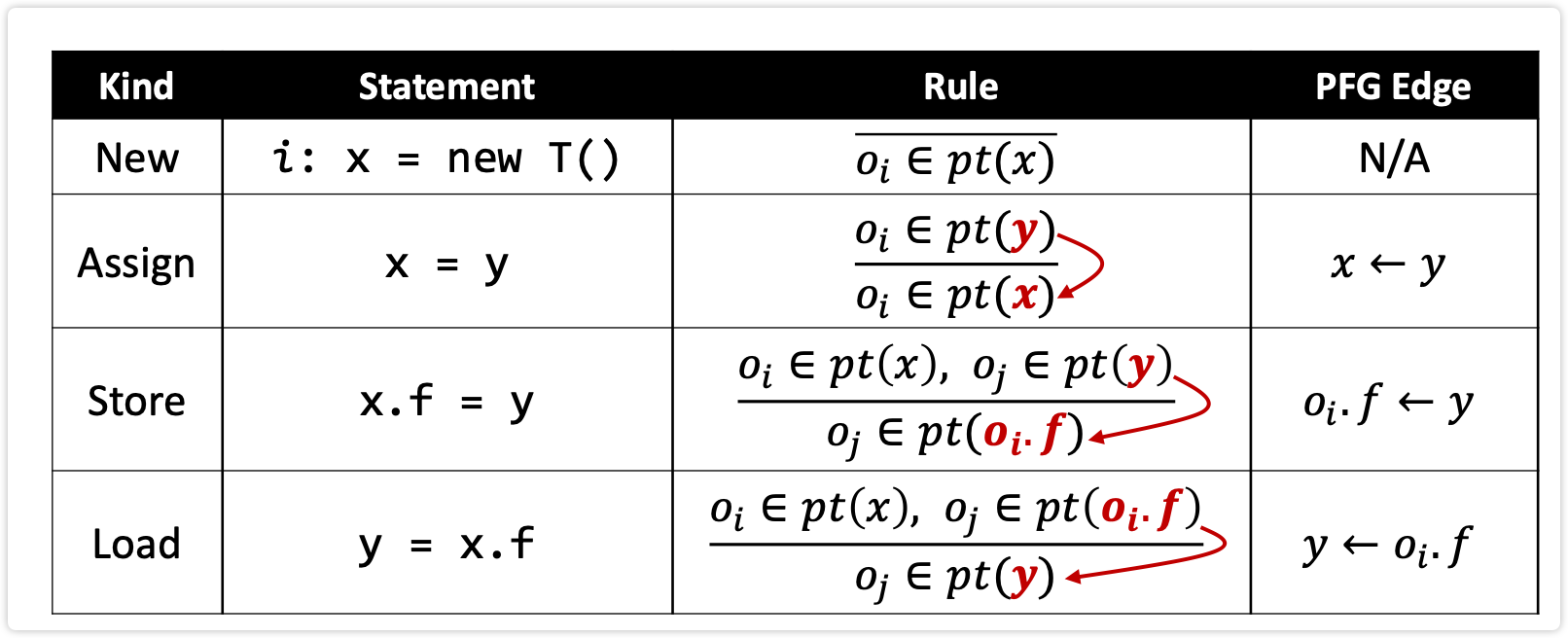
- premises c->oi d->oi
- a=b a<-b
- c.f=a oi.f<-a
- d=c d<-c
- c.f=d d->oi.f
- e=d.f oi.f->e
一个边只表示一步的的传播
指针分析要在图上找传递闭包
algorithm–只有new和assign的情况

相关数据结构
- WL:待处理的项
- 相当于pair的List,<pointer,P(O)>,前面是指针,后面是指某个集合
- PFG:算法中表示成了边的集合
- S输入的语句
左边的主算法
首先处理new语句,直接加到WL里面
再处理assign语句,相当于往PFG里加边
- 加边是需要注意更新workList
- 更新的规则,比如新增边是s->t,如果s指向的集合pt(s)不为空,则要在worklist里面加上,<t,Pt(s)> (s指向的对象会流向t指针)
对WL的处理
每次取一个pair ,取出<n,pts>,先删除pts集合中与n指针指向的集合重复的元素,把得到的集合传到propgate函数中,同时还要把n指针传进去

image-20231029175417544 prpgate函数:首先拓展n指针指向的集合,再把n的所有后继找出来,把pts加入他们指向的集合(先)
image-20231029175627084
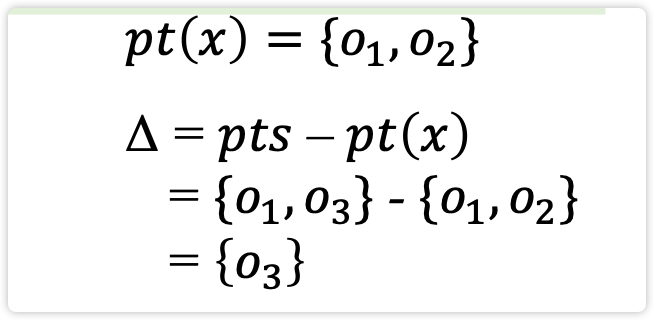

添加了计算差集的原因:差集是真正要传播的,这样做可以避免冗余操作
algorithm–store和load的情况

- store
- AddEdge
- x.f=y oi.f<-y
- 红框的部分不一定会在PFG里面加入新的边
- 虽然因为x.f=y要加入oi.f <- y这条边,但可能之前有另一个变量a也指向oi,所以oi.f <- y可能之前就加过了
- load
- AddEdge
- y=x.f y<-oi.f
- 也有上面说的问题
algorithm–总体

一个例子
1 | 1 b = new C(); |
oi表示是第i个语句中的对象
- 先处理new语句
- b=new C <b,{o1}>
- c=new C <c,{o3}>
- 上面两个都加到WL里面去
- 处理Assign语句
- a=b a{}<-b{}
- d=c d{}<-c{}
- 处理WL(需要看成是队列,先进先出)
- 处理<b,{o1}> a{}<-b{o1} <a,{o1}>加入WL
- 处理<c,{o3}> d{}<-c{o3} <d,{o3}>加入WL
- 由于存在c.f,要继续处理load/store c.f=a c.f=d
- 加边 o3.f{}<-a{} o3.f{}<-d{}
- 处理<a,{o1}> <o3.f,{o1}>加入WL
- 处理<d,{o3}> <o3.f,{o3}>加入WL
- d变量存在load e=d.f 加边o3.f->e
- 处理<o3.f,{o1}> <e,{o1}>也加入WL
- 处理<o3.f,{o3}> <e,{o3}>也加入WL
- 处理<e,{o1}> 直接改集合
- 处理<e,{o3}> 直接改集合

方法调用
针对的是在那些方法中的变量,由于方法在不同地方调用不同,同时传入的参数也不同,这使得处理方法调用比较麻烦


dispatch找到真正调用的方法
- 和CHA的类似
- 找到目标方法,存到变量m里
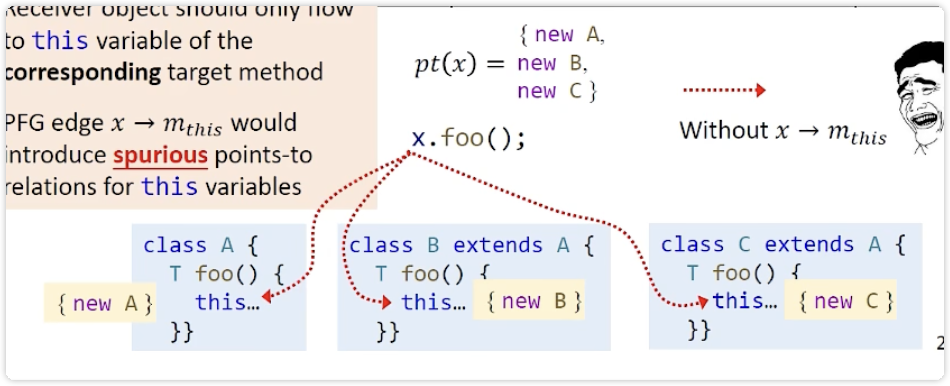
传receiver object (调用方法的对象)
虚线,但是x到this指针不是直接建立pfg中的边
image-20231031101710618 因为x可能指向多个对象,下图这种情况,如果直接建立x->this,会导致三个类的this都指向ABC(明显各类中通过dispatch找foo方法时,this只会是本身)
image-20231031102313325 解决方法:特殊处理,只传该传的
image-20231031102959408
传参数
- m是形参,a是实参
- 把实参和形参连起来(PFG中)
传返回值
- 函数中的ret传到外面的r变量中


algorithm
分析可达方法

输入为程序的entry方法,可以理解为main方法
S为可达语句的集合
RM为可达方法集合
CG call graph的边
algorithm–AddReachable
- 首先把传入的方法m加入RM集合(先判断m在不在RM中),m所在语句Sm也加入S集合中
- 处理new语句,加入WL
- 处理assign语句,调用addEdge
因为方法是新加进来的,指针集都是空的,还没办法做load和store (在后面的大循环中会被处理)
algorithm–ProcessCall
传入参数为x和oi
处理每条方法调用语句 l: r=x.k(a1,…,an)
- 通过dispatch定位到真正的方法m
- <m_this,{oi}>加到WL
- 如果l->m不在call graph中,则加入
- 之后继续处理参数,实参指向形参
- 传返回值
上下文敏感指针分析
motivation
使用上下文不敏感指针分析,分析出来i时1
根据常量传播,分析出来是NAC
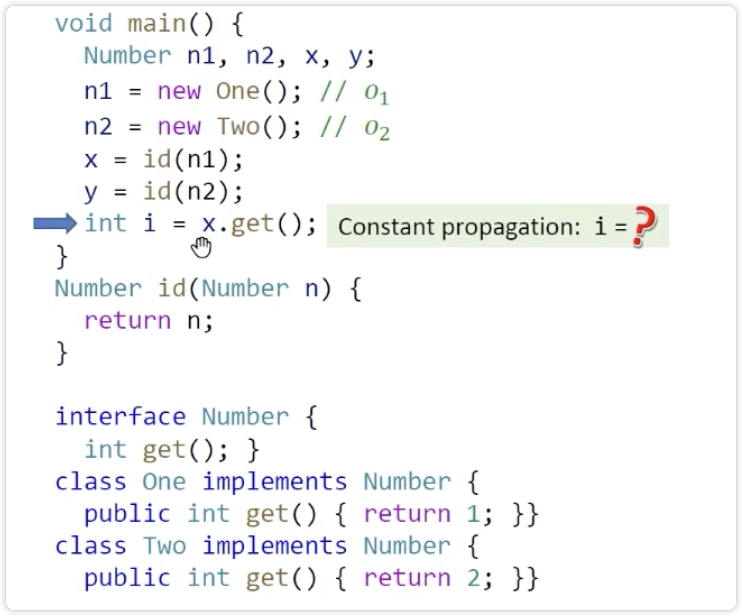

上下文敏感,方法调用时分开分析

克隆
给每个方法加以上下文修饰
以上面的程序为例,id有两个上下文,给id克隆两份

上下文敏感的Heap
上下文敏感还要加在堆抽象中,得到更细粒度的堆抽象
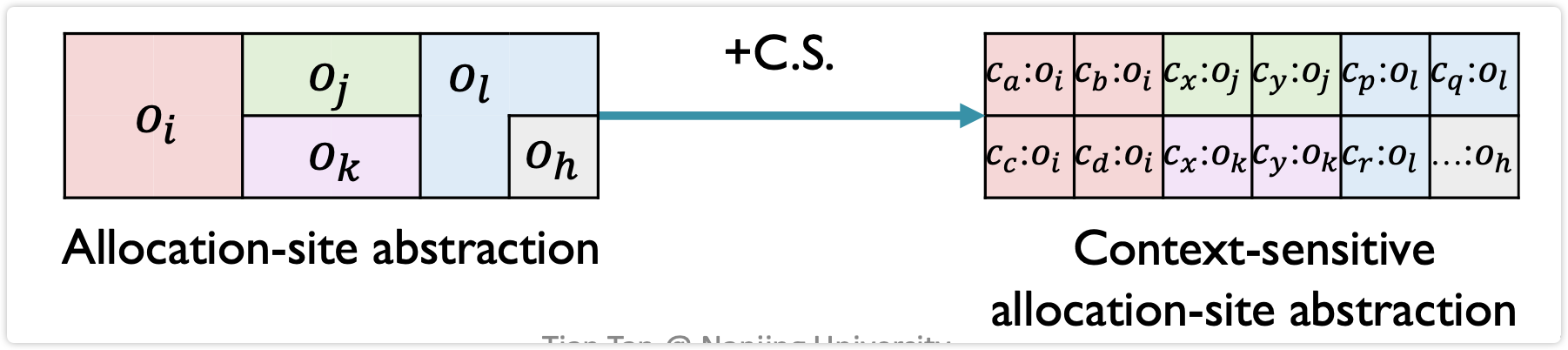
不同上下文创建的X,里面的field不一定一样

Heap–an example
1 | 1 n1 = new One(); |
对上面这段程序做指针分析,此时Heap上下文不敏感
- 先分析1、2, heap中
<n1,o1> <n2,o2> - 再分析3、7,
<3:p,o1> - 分析8
<3:x,o8> - 9、10
<o8.f,o1> <x1,3:o8>` - 4、7、8
<4:p,o2> <4:x,o8> - 9
<o8.f,{o1,o2}> - 5
<n,{o1,o2}>
Heap上下文敏感分析
- 1、2、3
<n1,o1> <n2,o2> <3:p,o1> - 8
<3:x,3:o8> - 9、10
<3:o8.f,o1> <x1,3:o8> - 4、7、8
<4:p,o2> <4:x,4:o8> - 9、10
<4:o8.f,o2> <x2:4:o8> - 5
<n,o1>
对比
提升了指针分析的精度

上下文敏感Heap,变量上下文不敏感
说明二者缺一不可

相关符号
用c、c’、c’’表示不同上下文
CSPointer上下文敏感的指针

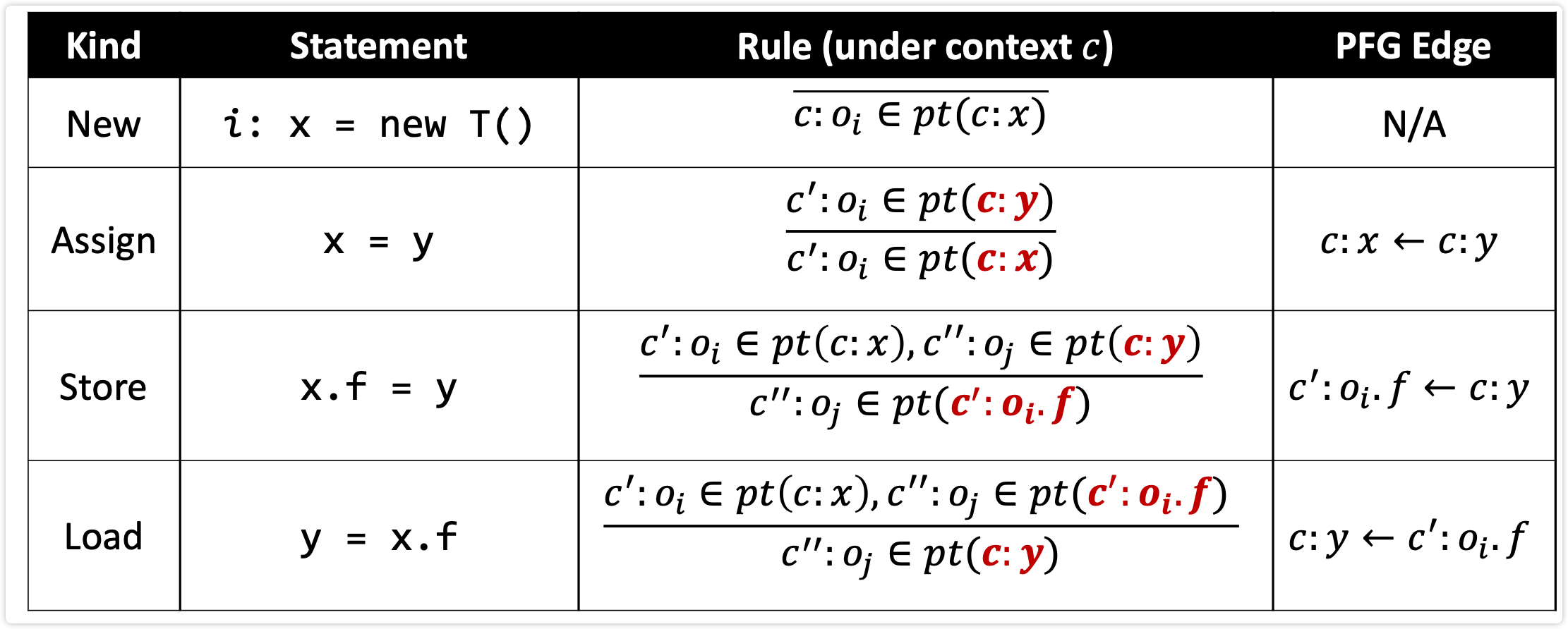
Rules
new语句 i: x = new T(); c:oi<-c:x
assign语句 x=y 已知 c:y-> c’:oi 则 c:x->c’:oi
store 已知x.f=y c:x.f->c’:oi y->c’’:oj 则c’:oi.f->c’’:oj
- c’和c’’可能是同一个,也可能不是同一个上下文
load 已知y=x.f c:x.f->c’:oi c’:oi.f->c’’:oj 则c:y->c’’:oj
call l: r = x
c:x->c’:oi
找目标方法,dispatch,然后根据调用点的信息算出来一个上下文c^t=Select(c,l,c’:oi,m)
相当于克隆,每遇到一个新的调用点,就会新增一个callee context
image-20231031201855315
实参和形参的对应
传return值,返回值的上下文是上面选出来的c^t

带有上下文信息的PFG
node:CSPointer
edges:CSPointer x CSPoniter
Call

上下文敏感指针分析算法
主题框架和上下文不敏感指针分析算法一致

- 首先给入口函数的上下文为[]
- entry方法加入可达方法
- 同时处理new和assign语句,更新WL
- 处理WL
- 更新WL中pair里指针对应的集合
- 如果指针是变量,则继续处理load和store
- 重点:ProcessCall,多了一个select
上下文敏感技术
- 调用敏感 k-CFA
- 类型敏感
- 对象敏感
- 标题: 软件分析-指针分析
- 作者: Sl0th
- 创建于 : 2023-10-17 18:47:28
- 更新于 : 2024-11-11 18:23:06
- 链接: http://sl0th.top/2023/10/17/软件分析-指针分析/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。